LLVM 迴圈術語 (與標準形式)¶
迴圈定義¶
迴圈是程式碼最佳化器的重要概念。在 LLVM 中,控制流程圖中的迴圈偵測是由 LoopInfo 完成的。它基於以下定義。
迴圈是控制流程圖 (CFG;其中節點代表基本區塊) 中節點的子集,具有以下屬性
誘導子圖 (它是包含迴圈內 CFG 中所有邊的子圖) 是強連通的 (每個節點都可以從所有其他節點到達)。
從子集外部到子集內部的所有邊都指向同一個節點,稱為標頭。 因此,標頭支配迴圈中的所有節點 (即,到達任何迴圈節點的每個執行路徑都必須通過標頭)。
迴圈是具有這些屬性的最大子集。 也就是說,不能添加來自 CFG 的其他節點,使得誘導子圖仍然是強連通的,並且標頭保持不變。
在電腦科學文獻中,這通常稱為自然迴圈。在 LLVM 中,更廣義的定義稱為 週期。
術語¶
迴圈的定義帶有一些額外的術語
進入區塊 (或迴圈前驅) 是一個非迴圈節點,它有一條邊進入迴圈 (必然是標頭)。 如果只有一個進入區塊,並且它唯一的邊是指向標頭的,則它也稱為迴圈的前置標頭。 前置標頭支配迴圈,但它本身不是迴圈的一部分。
閂鎖是一個迴圈節點,它有一條邊指向標頭。
回邊是從閂鎖到標頭的邊。
離開邊是從迴圈內部到迴圈外部節點的邊。 這種邊的來源稱為離開區塊,其目標是退出區塊。

重要注意事項¶
此迴圈定義有一些值得注意的後果
一個節點最多只能是一個迴圈的標頭。 因此,迴圈可以通過其標頭來識別。 由於標頭是進入迴圈的唯一入口,因此可以將其稱為單入口多出口 (SEME) 區域。
對於從函數入口無法到達的基本區塊,迴圈的概念是未定義的。 這也遵循支配的概念也是未定義的。
最小的迴圈由一個分支到自身的基本區塊組成。 在這種情況下,該區塊同時是標頭、閂鎖 (以及離開區塊,如果它有另一條邊到不同的區塊)。 單個沒有分支到自身區塊不被視為迴圈,即使它是平凡地強連通的。

在這種情況下,標頭、離開區塊和閂鎖的角色都落在同一個節點上。 LoopInfo 將此報告為
$ opt input.ll -passes='print<loops>'
Loop at depth 1 containing: %for.body<header><latch><exiting>
迴圈可以互相巢狀。 也就是說,一個迴圈的節點集可以是另一個具有不同迴圈標頭的迴圈的子集。 函數中的迴圈層次結構形成一個森林:每個頂層迴圈都是巢狀在其內部的迴圈樹的根。

兩個迴圈不可能只共享它們的一些節點。 兩個迴圈要么是不相交的,要么一個巢狀在另一個內部。 在下面的範例中,左側和右側子集都違反了最大性條件。 只有兩個集合的合併才被視為迴圈。

也可能兩個邏輯迴圈共享一個標頭,但被 LLVM 視為單個迴圈
for (int i = 0; i < 128; ++i)
for (int j = 0; j < 128; ++j)
body(i,j);
這在 LLVM-IR 中可能表示如下。 請注意,只有一個標頭,因此只有一個迴圈。

LoopSimplify 通行證將偵測迴圈並確保外部和內部迴圈有單獨的標頭。

CFG 中的週期並不意味著存在迴圈。 下面的範例顯示了這樣一個 CFG,其中沒有支配週期中所有其他節點的標頭節點。 這稱為不可約控制流程。

術語可約來自於將 CFG 折疊成單個節點的能力,方法是連續將三個基本結構之一替換為單個節點:基本區塊的順序執行、非循環條件分支 (或開關) 以及在自身上迴圈的基本區塊。 維基百科 有更正式的定義,基本上是說每個週期都有一個支配標頭。
不可約控制流程可能發生在迴圈巢狀的任何層級。 也就是說,本身不包含任何迴圈的迴圈在其主體中仍然可以具有循環控制流程; 未巢狀在另一個迴圈內的迴圈仍然可以是外部週期的一部分; 並且在一個包含在另一個中的任何兩個迴圈之間可能存在額外的週期。 然而,LLVM 週期 涵蓋了迴圈和不可約控制流程。
FixIrreducible 通行證可以通過插入新的迴圈標頭將不可約控制流程轉換為迴圈。 它不包含在任何預設最佳化通行證管道中,但某些後端目標需要它。
離開邊不是跳出迴圈的唯一方法。 其他可能性包括無法到達的終止符、[[noreturn]] 函數、例外、訊號和電腦的電源按鈕。
“在”迴圈內但沒有返回迴圈的路徑 (即到閂鎖或標頭) 的基本區塊不被視為迴圈的一部分。 以下程式碼說明了這一點。
for (unsigned i = 0; i <= n; ++i) {
if (c1) {
// When reaching this block, we will have exited the loop.
do_something();
break;
}
if (c2) {
// abort(), never returns, so we have exited the loop.
abort();
}
if (c3) {
// The unreachable allows the compiler to assume that this will not rejoin the loop.
do_something();
__builtin_unreachable();
}
if (c4) {
// This statically infinite loop is not nested because control-flow will not continue with the for-loop.
while(true) {
do_something();
}
}
}
控制流程沒有最終離開迴圈的要求,即迴圈可以是無限的。 靜態無限迴圈是沒有離開邊的迴圈。 動態無限迴圈有離開邊,但有可能永遠不會被採用。 這可能僅在某些情況下發生,例如當以下程式碼中的 n == UINT_MAX 時。
for (unsigned i = 0; i <= n; ++i)
body(i);
最佳化器有可能將動態無限迴圈變成靜態無限迴圈,例如,當它可以證明離開條件始終為假時。 因為永遠不會採用離開邊,所以最佳化器可以將條件分支更改為無條件分支。
如果迴圈用 llvm.loop.mustprogress metadata 註解,則編譯器可以假設它最終會終止,即使它無法證明這一點。 例如,即使程式可能永遠卡在該迴圈中,它也可能會刪除主體中沒有任何副作用的 mustprogress 迴圈。 C 和 C++ 等語言對於某些迴圈具有此類前向進度保證。 另請參閱 mustprogress 和 willreturn 函數屬性,以及較舊的 llvm.sideeffect 內建函數。
在離開迴圈之前,迴圈標頭的執行次數是迴圈行程計數 (或迭代計數)。 如果迴圈根本不應該執行,則迴圈守衛必須跳過整個迴圈

由於迴圈標頭可能做的第一件事是檢查是否還有另一次執行,如果沒有,則立即退出而不做任何工作 (另請參閱 旋轉迴圈),因此迴圈行程計數不是衡量迴圈迭代次數的最佳方法。 例如,以下程式碼對於非正數 n (在迴圈旋轉之前) 的標頭執行次數為 1,即使迴圈主體根本沒有執行。
for (int i = 0; i < n; ++i)
body(i);
更好的衡量標準是回邊採用計數,它是迴圈之前任何回邊被採用的次數。 對於進入標頭的執行,它比行程計數少 1。
LoopInfo¶
LoopInfo 是獲取迴圈資訊的核心分析。 上面給出的定義有一些關鍵的含義,對於成功使用此介面非常重要。
LoopInfo 不包含有關非迴圈週期的資訊。 因此,它不適用於任何需要完整週期偵測才能確保正確性的演算法。
LoopInfo 提供了一個介面,用於列舉所有頂層迴圈 (例如,那些不包含在任何其他迴圈中的迴圈)。 從那裡,您可以遍歷以該頂層迴圈為根的子迴圈樹。
在最佳化期間變成靜態無法到達的迴圈必須從 LoopInfo 中移除。 如果由於某些原因無法做到這一點,則要求最佳化保留迴圈的靜態可到達性。
迴圈簡化形式¶
迴圈簡化形式是一種標準形式,它使多種分析和轉換更簡單、更有效。 它由 LoopSimplify (-loop-simplify) 通行證確保,並在排程 LoopPass 時由通行證管理器自動添加。 此通行證在 LoopSimplify.h 中實作。 當它成功時,迴圈具有
前置標頭。
單個回邊 (這意味著只有一個閂鎖)。
專用出口。 也就是說,迴圈的任何出口區塊都沒有來自迴圈外部的前驅。 這意味著所有出口區塊都由迴圈標頭支配。
迴圈封閉 SSA (LCSSA)¶
如果程式處於 SSA 形式,並且迴圈中定義的所有值僅在迴圈內部使用,則該程式處於迴圈封閉 SSA 形式。
以 LLVM IR 撰寫的程式始終處於 SSA 形式,但不一定處於 LCSSA 形式。 為了實現後者,對於每個跨迴圈邊界存活的值,單入口 PHI 節點被插入到每個出口區塊 [1] 中,以便將這些值“封閉”在迴圈內。 特別是,考慮以下迴圈
c = ...;
for (...) {
if (c)
X1 = ...
else
X2 = ...
X3 = phi(X1, X2); // X3 defined
}
... = X3 + 4; // X3 used, i.e. live
// outside the loop
在內部迴圈中,X3 在迴圈內部定義,但在迴圈外部使用。 在迴圈封閉 SSA 形式中,這將表示如下
c = ...;
for (...) {
if (c)
X1 = ...
else
X2 = ...
X3 = phi(X1, X2);
}
X4 = phi(X3);
... = X4 + 4;
這仍然是有效的 LLVM; 額外的 phi 節點是純粹多餘的,但所有 LoopPass 都需要保留它們。 此形式由 LCSSA (-lcssa) 通行證確保,並在排程 LoopPass 時由 LoopPassManager 自動添加。 在迴圈最佳化完成後,這些額外的 phi 節點將被 -instcombine 刪除。
請注意,出口區塊在迴圈外部,那麼這樣的 phi 如何“封閉”迴圈內的值,因為它在迴圈外部使用它? 首先,對於 phi 節點,正如 LangRef 中提到的:“每個傳入值的使用都被認為發生在從相應的前驅區塊到當前區塊的邊上”。 現在,到出口區塊的邊被認為在迴圈外部,因為如果我們採用該邊,它會明確地將我們引導出迴圈。
但是,邊實際上不包含任何 IR,因此在原始碼中,我們必須選擇一個約定,即使用發生在當前區塊中還是發生在各自的前驅中。 為了 LCSSA 的目的,我們認為使用發生在後者中 (以便將使用視為內部) [2]。
LCSSA 的主要優點是它使許多其他迴圈最佳化更簡單。
首先,一個簡單的觀察是,如果需要查看所有外部使用者,他們可以只迭代出口區塊中的所有 (迴圈封閉) PHI 節點 (另一種方法是掃描迴圈中所有指令的 def-use 鏈 [3])。
然後,考慮例如 simple-loop-unswitch 上面迴圈的 ing。 因為它處於 LCSSA 形式,我們知道在迴圈內部定義的任何值將僅在迴圈內部或在迴圈封閉 PHI 節點中使用。 在這種情況下,唯一的迴圈封閉 PHI 節點是 X4。 這意味著我們可以簡單地複製迴圈並相應地更改 X4,如下所示
c = ...;
if (c) {
for (...) {
if (true)
X1 = ...
else
X2 = ...
X3 = phi(X1, X2);
}
} else {
for (...) {
if (false)
X1' = ...
else
X2' = ...
X3' = phi(X1', X2');
}
}
X4 = phi(X3, X3')
現在,X4 的所有使用都會獲得更新的值 (一般來說,如果迴圈處於 LCSSA 形式,在任何迴圈轉換中,我們只需要更新迴圈封閉 PHI 節點即可使更改生效)。 如果我們沒有迴圈封閉 SSA 形式,則意味著 X3 可能在迴圈外部使用。 因此,我們必須引入 X4 (即新的 X3) 並將 X3 的所有使用替換為它。 但是,我們應該注意,因為 LLVM 為每個值保留了 def-use 鏈 [3],我們不需要執行資料流程分析來尋找和替換所有使用 (甚至有一個實用函數 replaceAllUsesWith(),它通過迭代 def-use 鏈來執行此轉換)。
另一個重要的優點是歸納變數的所有使用的行為都是相同的。 如果沒有這個,您需要區分變數在定義它的迴圈外部使用時的情況,例如
for (i = 0; i < 100; i++) {
for (j = 0; j < 100; j++) {
k = i + j;
use(k); // use 1
}
use(k); // use 2
}
從具有正常 SSA 形式的外部迴圈來看,k 的第一次使用行為不佳,而第二次使用是基數為 100,步長為 1 的歸納變數。 儘管在實踐中,以及在 LLVM 環境中,SCEV 可以有效地處理這種情況。 標量演化 (scalar-evolution) 或 SCEV 是一個 (分析) 通行證,用於分析和分類迴圈中標量表示式的演化。
通常,在 LCSSA 形式的迴圈中使用 SCEV 更容易。 SCEV 可以分析的標量 (迴圈變體) 表示式的演化,根據定義,是相對於迴圈的。 表示式在 LLVM 中由 llvm::Instruction 表示。 如果表示式在兩個 (或更多) 迴圈內部 (只有當迴圈是巢狀時才會發生,就像上面的範例中那樣),並且您想要獲得其演化 (來自 SCEV) 的分析,您還必須指定相對於哪個迴圈您想要它。 具體來說,您必須使用 getSCEVAtScope()。
但是,如果所有迴圈都處於 LCSSA 形式,則每個表示式實際上由兩個不同的 llvm::Instructions 表示。 一個在迴圈內部,另一個在外部,它是迴圈封閉 PHI 節點,表示最後一次迭代後表示式的值 (實際上,我們將每個迴圈變體表示式分成兩個表示式,因此,每個表示式最多在一個迴圈中)。 您現在可以只使用 getSCEV()。 並且您傳遞給它的這兩個 llvm::Instructions 中的哪一個消除了上下文/作用域/相對迴圈的歧義。
腳註
“更標準”的迴圈¶
旋轉迴圈¶
迴圈通過 LoopRotate (loop-rotate) 通行證旋轉,它將迴圈轉換為 do/while 樣式迴圈,並在 LoopRotation.h 中實作。 範例
void test(int n) {
for (int i = 0; i < n; i += 1)
// Loop body
}
轉換為
void test(int n) {
int i = 0;
do {
// Loop body
i += 1;
} while (i < n);
}
警告:僅當編譯器可以證明迴圈主體將至少執行一次時,此轉換才有效。 否則,它必須插入一個守衛,在運行時測試它。 在上面的範例中,那將是
void test(int n) {
int i = 0;
if (n > 0) {
do {
// Loop body
i += 1;
} while (i < n);
}
}
重要的是要了解迴圈旋轉在 LLVM IR 層級的效果。 我們繼續使用先前的 LLVM IR 範例,同時也提供控制流程圖 (CFG) 的圖形表示。 您可以使用 view-cfg 通行證獲得相同的圖形結果。
最初的 for 迴圈可以翻譯成
define void @test(i32 %n) {
entry:
br label %for.header
for.header:
%i = phi i32 [ 0, %entry ], [ %i.next, %latch ]
%cond = icmp slt i32 %i, %n
br i1 %cond, label %body, label %exit
body:
; Loop body
br label %latch
latch:
%i.next = add nsw i32 %i, 1
br label %for.header
exit:
ret void
}
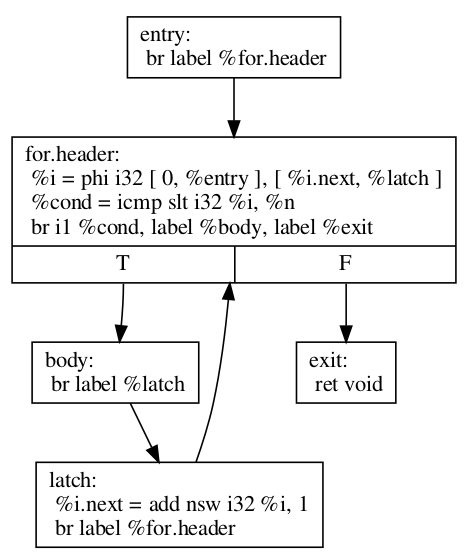
在我們解釋 LoopRotate 實際上將如何轉換此迴圈之前,這是我們如何 (手動) 將其轉換為 do-while 樣式迴圈的方法。
define void @test(i32 %n) {
entry:
br label %body
body:
%i = phi i32 [ 0, %entry ], [ %i.next, %latch ]
; Loop body
br label %latch
latch:
%i.next = add nsw i32 %i, 1
%cond = icmp slt i32 %i.next, %n
br i1 %cond, label %body, label %exit
exit:
ret void
}
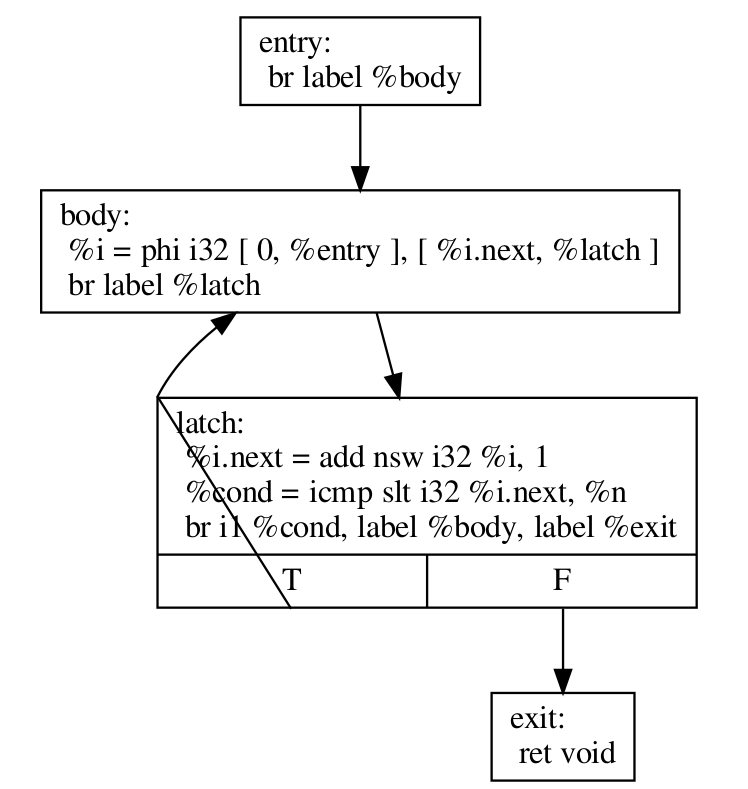
請注意兩件事
條件檢查已移至迴圈的“底部”,即閂鎖。 這是 LoopRotate 通過將迴圈的標頭複製到閂鎖來完成的事情。
在這種情況下,編譯器無法推斷迴圈肯定會至少執行一次,因此上面的轉換無效。 如上所述,必須插入一個守衛,這是 LoopRotate 將要做的事情。
這是 LoopRotate 轉換此迴圈的方式
define void @test(i32 %n) {
entry:
%guard_cond = icmp slt i32 0, %n
br i1 %guard_cond, label %loop.preheader, label %exit
loop.preheader:
br label %body
body:
%i2 = phi i32 [ 0, %loop.preheader ], [ %i.next, %latch ]
br label %latch
latch:
%i.next = add nsw i32 %i2, 1
%cond = icmp slt i32 %i.next, %n
br i1 %cond, label %body, label %loop.exit
loop.exit:
br label %exit
exit:
ret void
}
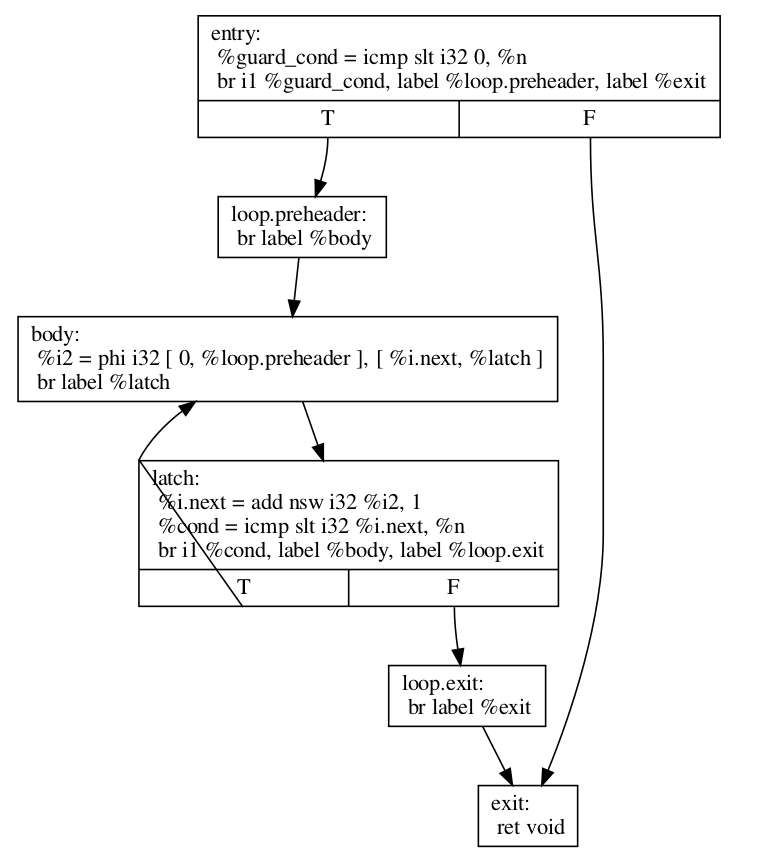
結果比我們預期的要複雜一點,因為 LoopRotate 確保迴圈在旋轉後處於 迴圈簡化形式。 在這種情況下,它插入了 %loop.preheader 基本區塊,以便迴圈具有前置標頭,並引入了 %loop.exit 基本區塊,以便迴圈具有專用出口 (否則,%exit 將從 %latch 和 %entry 跳轉,但 %entry 不包含在迴圈中)。 請注意,迴圈也必須事先處於迴圈簡化形式,才能成功應用 LoopRotate。
這種形式的主要優點是它允許將不變指令 (尤其是載入) 提升到前置標頭中。 這也可以在非旋轉迴圈中完成,但有一些缺點。 讓我們用一個範例來說明它們
for (int i = 0; i < n; ++i) {
auto v = *p;
use(v);
}
我們假設從 p 載入是不變的,use(v) 是一些使用 v 的陳述。 如果我們只想執行一次載入,我們可以將其“移出”迴圈主體,從而得到這個
auto v = *p;
for (int i = 0; i < n; ++i) {
use(v);
}
但是,現在,在 n <= 0 的情況下,在初始形式中,迴圈主體永遠不會執行,因此,載入永遠不會執行。 這主要是語義原因的問題。 考慮 n <= 0 且從 p 載入無效的情況。 在初始程式中不會有錯誤。 但是,通過這種轉換,我們將引入一個錯誤,從而有效地破壞初始語義。
為了避免這兩個問題,我們可以插入一個守衛
if (n > 0) { // loop guard
auto v = *p;
for (int i = 0; i < n; ++i) {
use(v);
}
}
這當然更好,但可以稍微改進一下。 請注意,檢查 n 是否大於 0 執行了兩次 (並且 n 在這之間沒有改變)。 一次是當我們檢查守衛條件時,另一次是在迴圈的第一次執行中。 為了避免這種情況,我們可以進行無條件的第一次執行,並在最後插入迴圈條件。 這實際上意味著將迴圈轉換為 do-while 迴圈
if (0 < n) {
auto v = *p;
do {
use(v);
++i;
} while (i < n);
}
請注意,LoopRotate 通常不執行這種提升。 相反,它是其他通行證 (如迴圈不變程式碼移動 (-licm)) 的啟用轉換。