LLVM 中的自動向量化¶
LLVM 有兩個向量化器:迴圈向量化器,其作用於迴圈;以及 SLP 向量化器。這些向量化器專注於不同的最佳化機會並使用不同的技術。SLP 向量化器將程式碼中找到的多個純量合併為向量,而迴圈向量化器擴展迴圈中的指令以對多個連續迭代進行操作。
迴圈向量化器和 SLP 向量化器預設皆為啟用。
迴圈向量化器¶
使用方式¶
迴圈向量化器預設為啟用,但可以使用 clang 命令列旗標停用它
$ clang ... -fno-vectorize file.c
命令列旗標¶
迴圈向量化器使用成本模型來決定最佳向量化因子和展開因子。但是,向量化器的使用者可以強制向量化器使用特定值。「clang」和「opt」都支援以下旗標。
使用者可以使用命令列旗標「-force-vector-width」來控制向量化 SIMD 寬度。
$ clang -mllvm -force-vector-width=8 ...
$ opt -loop-vectorize -force-vector-width=8 ...
使用者可以使用命令列旗標「-force-vector-interleave」來控制展開因子
$ clang -mllvm -force-vector-interleave=2 ...
$ opt -loop-vectorize -force-vector-interleave=2 ...
Pragma 迴圈提示指令¶
#pragma clang loop 指令允許為後續的 for、while、do-while 或 c++11 基於範圍的 for 迴圈指定迴圈向量化提示。該指令允許啟用或停用向量化和交錯。也可以手動指定向量寬度和交錯計數。以下範例明確啟用向量化和交錯
#pragma clang loop vectorize(enable) interleave(enable)
while(...) {
...
}
以下範例透過指定向量寬度和交錯計數來隱含地啟用向量化和交錯
#pragma clang loop vectorize_width(2) interleave_count(2)
for(...) {
...
}
有關詳細資訊,請參閱 Clang 語言擴展。
診斷¶
許多迴圈無法向量化,包括具有複雜控制流程、不可向量化型別和不可向量化呼叫的迴圈。迴圈向量化器產生最佳化註解,可以使用命令列選項查詢這些註解,以識別和診斷被迴圈向量化器跳過的迴圈。
使用以下命令啟用最佳化註解
-Rpass=loop-vectorize 識別已成功向量化的迴圈。
-Rpass-missed=loop-vectorize 識別向量化失敗的迴圈,並指示是否已指定向量化。
-Rpass-analysis=loop-vectorize 識別導致向量化失敗的語句。如果另外提供 -fsave-optimization-record,則可能會列出多個向量化失敗的原因(此行為將來可能會變更)。
考慮以下迴圈
#pragma clang loop vectorize(enable)
for (int i = 0; i < Length; i++) {
switch(A[i]) {
case 0: A[i] = i*2; break;
case 1: A[i] = i; break;
default: A[i] = 0;
}
}
命令列 -Rpass-missed=loop-vectorize 印出註解
no_switch.cpp:4:5: remark: loop not vectorized: vectorization is explicitly enabled [-Rpass-missed=loop-vectorize]
命令列 -Rpass-analysis=loop-vectorize 指示 switch 語句無法向量化。
no_switch.cpp:4:5: remark: loop not vectorized: loop contains a switch statement [-Rpass-analysis=loop-vectorize]
switch(A[i]) {
^
若要確保產生行號和列號,請包含命令列選項 -gline-tables-only 和 -gcolumn-info。有關詳細資訊,請參閱 Clang 使用者手冊
功能¶
LLVM 迴圈向量化器具有許多功能,使其能夠向量化複雜的迴圈。
迴圈次數未知的迴圈¶
迴圈向量化器支援迴圈次數未知的迴圈。在下面的迴圈中,迭代的 start 和 finish 點是未知的,並且迴圈向量化器具有向量化非從零開始的迴圈的機制。在此範例中,「n」可能不是向量寬度的倍數,並且向量化器必須將最後幾次迭代作為純量程式碼執行。保留迴圈的純量副本會增加程式碼大小。
void bar(float *A, float* B, float K, int start, int end) {
for (int i = start; i < end; ++i)
A[i] *= B[i] + K;
}
指標的執行時期檢查¶
在以下範例中,如果指標 A 和 B 指向連續的位址,則向量化程式碼是非法的,因為 A 的某些元素將在從陣列 B 讀取之前被寫入。
一些程式設計師使用 'restrict' 關鍵字來通知編譯器指標是不相交的,但在我們的範例中,迴圈向量化器無法得知指標 A 和 B 是唯一的。迴圈向量化器透過放置程式碼來處理此迴圈,該程式碼在執行時期檢查陣列 A 和 B 是否指向不相交的記憶體位置。如果陣列 A 和 B 重疊,則執行迴圈的純量版本。
void bar(float *A, float* B, float K, int n) {
for (int i = 0; i < n; ++i)
A[i] *= B[i] + K;
}
歸約¶
在此範例中,sum 變數被迴圈的連續迭代使用。通常,這會阻止向量化,但向量化器可以偵測到 'sum' 是一個歸約變數。變數 'sum' 變成整數向量,並且在迴圈結束時,陣列的元素被加在一起以產生正確的結果。我們支援許多不同的歸約運算,例如加法、乘法、互斥或、AND 和 OR。
int foo(int *A, int n) {
unsigned sum = 0;
for (int i = 0; i < n; ++i)
sum += A[i] + 5;
return sum;
}
當使用 -ffast-math 時,我們支援浮點歸約運算。
歸納¶
在此範例中,歸納變數 i 的值被儲存到陣列中。迴圈向量化器知道要向量化歸納變數。
void bar(float *A, int n) {
for (int i = 0; i < n; ++i)
A[i] = i;
}
If 轉換¶
迴圈向量化器能夠「展平」程式碼中的 IF 語句並產生單一指令流。迴圈向量化器支援最內層迴圈中的任何控制流程。最內層迴圈可能包含 IF、ELSE 甚至 GOTO 的複雜巢狀結構。
int foo(int *A, int *B, int n) {
unsigned sum = 0;
for (int i = 0; i < n; ++i)
if (A[i] > B[i])
sum += A[i] + 5;
return sum;
}
指標歸納變數¶
此範例使用標準 c++ 程式庫的 "accumulate" 函式。此迴圈使用 C++ 迭代器(指標)而不是整數索引。迴圈向量化器偵測指標歸納變數並且可以向量化此迴圈。此功能很重要,因為許多 C++ 程式都使用迭代器。
int baz(int *A, int n) {
return std::accumulate(A, A + n, 0);
}
反向迭代器¶
迴圈向量化器可以向量化向後計數的迴圈。
void foo(int *A, int n) {
for (int i = n; i > 0; --i)
A[i] +=1;
}
分散 / 聚集¶
迴圈向量化器可以向量化變成一系列純量指令的程式碼,這些指令分散/聚集記憶體。
void foo(int * A, int * B, int n) {
for (intptr_t i = 0; i < n; ++i)
A[i] += B[i * 4];
}
在許多情況下,成本模型會告知 LLVM 這沒有好處,並且 LLVM 僅在強制使用 "-mllvm -force-vector-width=#" 時才會向量化此類程式碼。
混合型別的向量化¶
迴圈向量化器可以向量化具有混合型別的程式。向量化器成本模型可以估計型別轉換的成本,並決定向量化是否有利可圖。
void foo(int *A, char *B, int n) {
for (int i = 0; i < n; ++i)
A[i] += 4 * B[i];
}
全域結構別名分析¶
對全域結構的存取也可以向量化,並使用別名分析來確保存取不會產生別名。也可以在指標存取結構成員時新增執行時期檢查。
支援許多變體,但一些依賴未定義行為被忽略(如同其他編譯器所做的那樣)的變體仍然未被向量化。
struct { int A[100], K, B[100]; } Foo;
void foo() {
for (int i = 0; i < 100; ++i)
Foo.A[i] = Foo.B[i] + 100;
}
函式呼叫的向量化¶
迴圈向量化器可以向量化內建數學函式。請參閱下表以取得這些函式的列表。
pow |
exp |
exp2 |
sin |
cos |
sqrt |
log |
log2 |
log10 |
fabs |
floor |
ceil |
fma |
trunc |
nearbyint |
fmuladd |
請注意,如果程式庫呼叫存取外部狀態(例如「errno」),則最佳化器可能無法向量化對應於這些內建函式的數學程式庫函式。若要允許更好地最佳化 C/C++ 數學程式庫函式,請使用「-fno-math-errno」。
迴圈向量化器知道目標上的特殊指令,並且如果迴圈包含對應於指令的函式呼叫,則會向量化該迴圈。例如,如果 SSE4.1 roundps 指令可用,則以下迴圈將在 Intel x86 上向量化。
void foo(float *f) {
for (int i = 0; i != 1024; ++i)
f[i] = floorf(f[i]);
}
如果檔案已使用指定的目標向量程式庫建置,而該程式庫提供該數學函式的向量實作,則許多這些數學函式才能向量化。使用 clang 時,這由 "-fveclib" 命令列選項處理,並使用以下向量程式庫之一:「accelerate,libmvec,massv,svml,sleef,darwin_libsystem_m,armpl,amdlibm」
$ clang ... -fno-math-errno -fveclib=libmvec file.c
向量化期間的部分展開¶
現代處理器具有多個執行單元,只有包含高度並行性的程式才能充分利用機器的整個寬度。迴圈向量化器透過執行迴圈的部分展開來增加指令級並行性 (ILP)。
在以下範例中,整個陣列被累積到變數 'sum' 中。這是低效的,因為處理器只能使用單一執行埠。透過展開程式碼,迴圈向量化器允許同時使用兩個或多個執行埠。
int foo(int *A, int n) {
unsigned sum = 0;
for (int i = 0; i < n; ++i)
sum += A[i];
return sum;
}
迴圈向量化器使用成本模型來決定何時展開迴圈有利可圖。展開迴圈的決定取決於暫存器壓力和產生的程式碼大小。
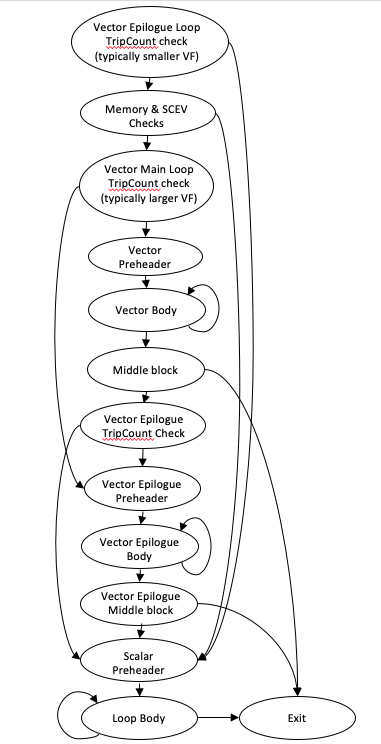
後記向量化¶
當向量化迴圈時,如果迴圈次數未知或它不能均勻地除以向量化和展開因子,則通常需要純量餘數(後記)迴圈來執行迴圈的尾端迭代。當向量化和展開因子很大時,迴圈次數較小的迴圈可能會將大部分時間花費在純量(而不是向量)程式碼中。為了解決此問題,內部迴圈向量化器增強了一項功能,使其能夠向量化後記迴圈,並結合向量化和展開因子,使其更有可能讓小迴圈次數的迴圈仍然在向量化程式碼中執行。下圖顯示了具有執行時期檢查的典型後記向量化迴圈的 CFG。如圖所示,控制流程的結構方式避免了重複執行時期指標檢查,並最佳化了迴圈次數非常小的迴圈的路徑長度。
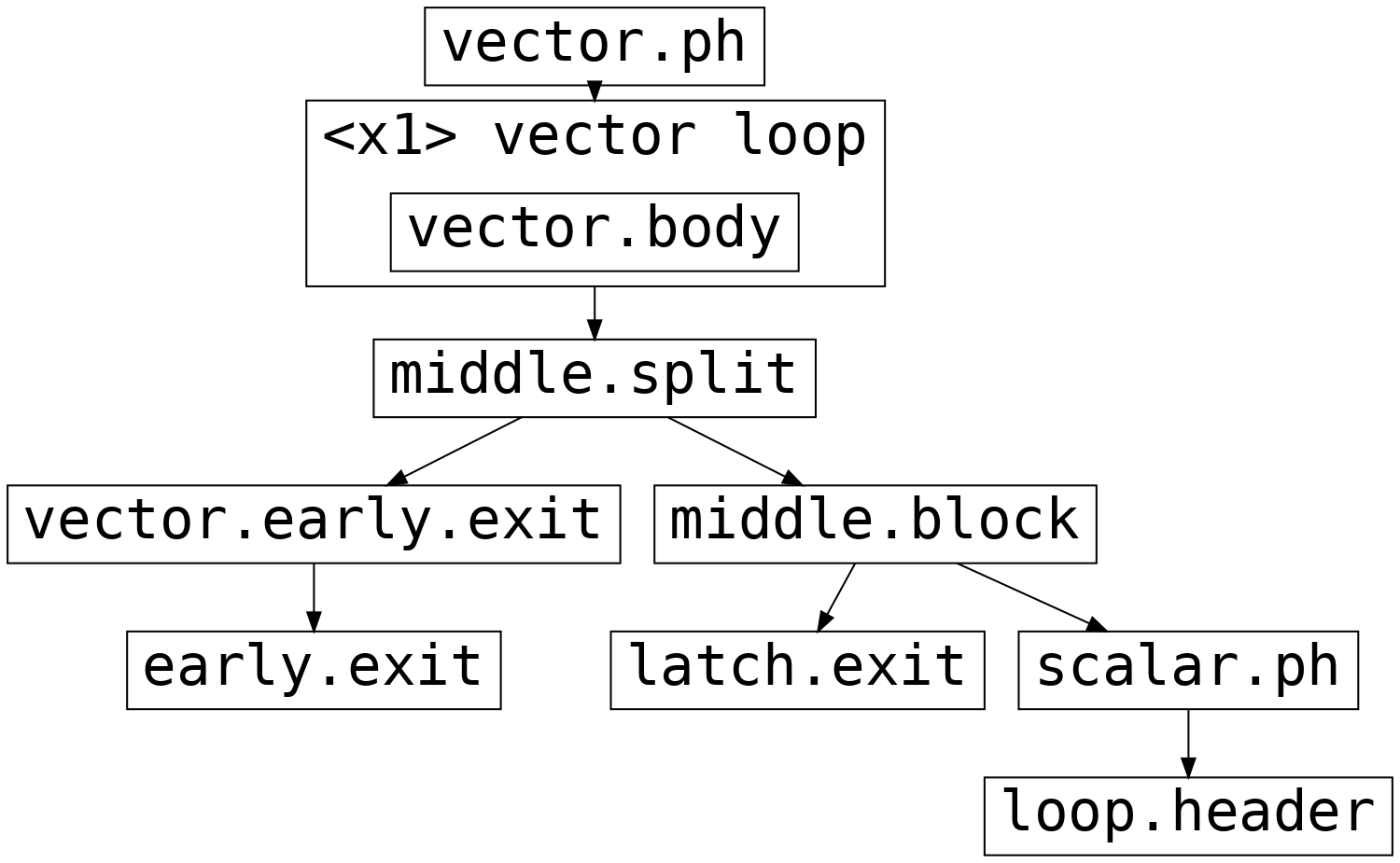
提早退出向量化¶
當向量化具有單一提早退出的迴圈時,提早退出後的迴圈區塊會被預測,並且向量迴圈將始終透過閂鎖退出。如果已採用提早退出,則向量迴圈的後繼區塊(下方的 middle.split)會透過中間區塊(下方的 vector.early.exit)分支到提早退出區塊。此中間區塊負責計算提早退出區塊中使用的迴圈定義變數的任何退出值。否則,middle.block 會在來自閂鎖或純量餘數迴圈的退出區塊之間進行選擇。
效能¶
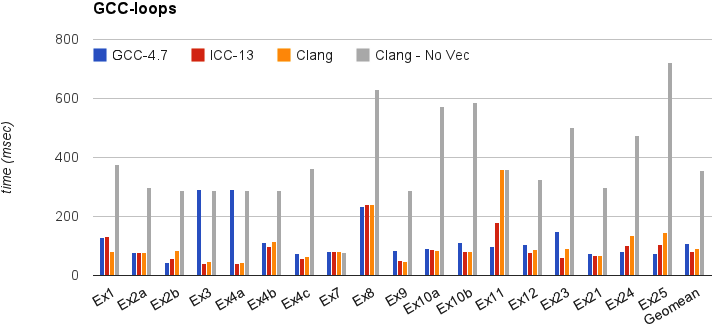
本節顯示 Clang 在簡單基準測試上的執行時間:gcc-loops。此基準測試是 Dorit Nuzman 提供的 GCC 自動向量化 頁面中的迴圈集合。
下圖比較了 GCC-4.7、ICC-13 和 Clang-SVN 在 -O3 下,針對 “corei7-avx” 調整,在 Sandybridge iMac 上執行時,有無迴圈向量化的情況。Y 軸顯示時間,單位為毫秒 (msec)。數值越低越好。最後一欄顯示所有核心的幾何平均值。
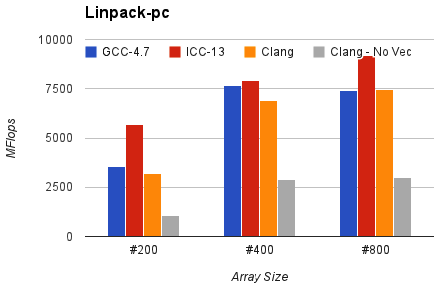
以及具有相同組態的 Linpack-pc。結果為 Mflops,數值越高越好。
持續開發方向¶
- 向量化計畫
為 LLVM 迴圈向量化器的流程建模並升級基礎架構。
SLP 向量化器¶
詳細資訊¶
SLP 向量化(又名超字級並行性)的目標是將類似的獨立指令組合到向量指令中。記憶體存取、算術運算、比較運算、PHI 節點都可以使用此技術進行向量化。
例如,以下函式對其輸入 (a1, b1) 和 (a2, b2) 執行非常相似的運算。基本區塊向量化器可能會將這些運算組合到向量運算中。
void foo(int a1, int a2, int b1, int b2, int *A) {
A[0] = a1*(a1 + b1);
A[1] = a2*(a2 + b2);
A[2] = a1*(a1 + b1);
A[3] = a2*(a2 + b2);
}
SLP 向量化器在基本區塊之間以由下而上的方式處理程式碼,以搜尋要組合的純量。
使用方式¶
SLP 向量化器預設為啟用,但可以使用 clang 命令列旗標停用它
$ clang -fno-slp-vectorize file.c