推測性載入強化¶
Spectre 變種 #1 的緩解技術¶
作者:Chandler Carruth - chandlerc@google.com
問題陳述¶
近期,Google Project Zero 和其他研究人員發現,現代 CPU 中的推測性執行存在資訊洩漏漏洞。這些漏洞目前被歸類為三個變種:
GPZ 變種 #1 (又名 Spectre 變種 #1):邊界檢查(或謂詞)繞過
GPZ 變種 #2 (又名 Spectre 變種 #2):分支目標注入
GPZ 變種 #3 (又名 Meltdown):惡意資料快取載入
欲了解更多詳細資訊,請參閱 Google Project Zero 部落格文章和 Spectre 研究論文
https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
https://spectreattack.com/spectre.pdf
GPZ 變種 #1 的核心問題在於,推測性執行使用分支預測來選擇推測性執行的指令路徑。此路徑會使用可用資料進行推測性執行,並可能從記憶體載入資料,並透過各種側通道洩漏載入的值,即使推測性執行因不正確而被回溯,這些側通道仍然存在。預測錯誤的路徑可能導致程式碼使用在正確執行中永遠不會出現的資料輸入來執行,使得針對惡意輸入的檢查失效,並允許攻擊者使用惡意資料輸入來洩漏機密資料。以下範例摘錄並簡化自 Project Zero 論文:
struct array {
unsigned long length;
unsigned char data[];
};
struct array *arr1 = ...; // small array
struct array *arr2 = ...; // array of size 0x400
unsigned long untrusted_offset_from_caller = ...;
if (untrusted_offset_from_caller < arr1->length) {
unsigned char value = arr1->data[untrusted_offset_from_caller];
unsigned long index2 = ((value&1)*0x100)+0x200;
unsigned char value2 = arr2->data[index2];
}
此攻擊的關鍵在於使用 untrusted_offset_from_caller 呼叫此函數,當分支預測器預測其將在界限內時,該值遠遠超出界限。在這種情況下,if 的主體將被推測性執行,並可能將機密資料讀取到 value 中,並在進行依賴性存取以填充 value2 時,透過快取時序側通道洩漏該資料。
高階緩解方法¶
雖然目前正積極尋求多種方法來緩解高風險軟體(最顯著的是各種作業系統核心)中特定的分支和/或載入,但這些方法需要人工和/或靜態分析輔助的代码審計,以及顯式的原始碼變更才能應用緩解措施。它們不太可能很好地擴展到大型應用程式。我們正在提出一種全面的緩解方法,該方法將自動應用於整個程式,而不是透過手動變更程式碼。雖然這可能會產生很高的效能成本,但某些應用程式可能很適合接受這種效能/安全性權衡。
我們提出的具體技術是使用無分支程式碼來檢查載入,以確保它們沿著有效的控制流程路徑執行。請考慮以下 C 偽代碼,它代表了謂詞保護潛在無效載入的核心思想:
void leak(int data);
void example(int* pointer1, int* pointer2) {
if (condition) {
// ... lots of code ...
leak(*pointer1);
} else {
// ... more code ...
leak(*pointer2);
}
}
這將轉換成類似於以下的程式碼:
uintptr_t all_ones_mask = std::numerical_limits<uintptr_t>::max();
uintptr_t all_zeros_mask = 0;
void leak(int data);
void example(int* pointer1, int* pointer2) {
uintptr_t predicate_state = all_ones_mask;
if (condition) {
// Assuming ?: is implemented using branchless logic...
predicate_state = !condition ? all_zeros_mask : predicate_state;
// ... lots of code ...
//
// Harden the pointer so it can't be loaded
pointer1 &= predicate_state;
leak(*pointer1);
} else {
predicate_state = condition ? all_zeros_mask : predicate_state;
// ... more code ...
//
// Alternative: Harden the loaded value
int value2 = *pointer2 & predicate_state;
leak(value2);
}
}
結果應該是,如果 if (condition) { 分支被錯誤預測,則在用於將任何指標歸零(在透過它們載入之前)或將所有載入位元歸零的條件上存在資料依賴性。即使此程式碼模式可能仍會推測性執行,無效的推測性執行也會被阻止從記憶體中洩漏機密資料(但請注意,此資料可能仍以安全的方式載入,並且某些記憶體區域需要不包含機密資訊,請參閱下文了解詳細限制)。此方法僅要求底層硬體具有一種方法來實作暫存器值的無分支且不可預測的條件更新。所有現代架構都支援此功能,事實上,這種支援對於正確實作恆定時間加密原語是必要的。
此方法的關鍵特性
它並非阻止任何特定的側通道運作。這一點很重要,因為存在未知數量的潛在側通道,而且我們預計將繼續發現更多。相反,它首先阻止了機密資料的觀察。
它累積了謂詞狀態,即使在面對巢狀正確預測的控制流程時也能提供保護。
它跨函數邊界傳遞此謂詞狀態,以提供程序間保護。
在強化載入位址時,它使用破壞性或不可逆的位址修改,以防止攻擊者使用攻擊者控制的輸入來反轉檢查。
它不會完全阻止推測性執行,而僅僅阻止錯誤推測的路徑從記憶體中洩漏機密資訊(並暫停推測,直到可以確定這一點)。
它是完全通用的,並且除了能夠執行無分支條件資料更新和缺乏值預測之外,沒有對底層架構做出任何基本假設。
它不需要程式設計師使用靜態原始碼註解或容易受到變種 #1 樣式攻擊的程式碼來識別所有可能的機密資料。
此方法的限制
它需要重新編譯原始碼以插入強化指令序列。只有在此模式下編譯的軟體才能受到保護。
效能高度依賴於特定架構的實作策略。我們在下面概述了一個潛在的 x86 實作,並描述了其效能。
它無法防禦已從記憶體載入並駐留在暫存器中,或在非推測性執行中透過其他側通道洩漏的機密資料。處理此問題的程式碼(例如加密例程)已經使用恆定時間演算法和程式碼來防止側通道。此類程式碼也應遵循這些指南清除暫存器中的機密資料。
為了實現合理的效能,許多載入可能不會被檢查,例如那些具有編譯時期固定位址的載入。這主要包括在全域和區域變數的編譯時期常數偏移量處的存取。需要此保護並有意儲存機密資料的程式碼必須確保用於機密資料的記憶體區域必須是動態映射或堆積分配。這是一個可以調整的領域,以提供更全面的保護,但會犧牲效能。
強化的載入仍然可能從有效位址載入資料,如果不是攻擊者控制的位址。為了防止這些載入讀取機密資料,應保護位址空間的低 2GB 以及任何可執行頁面上方和下方的 2GB 範圍。
致謝
透過資料追蹤錯誤推測並標記指標以阻止錯誤推測載入的核心思想,是在 Chandler Carruth、Paul Kocher、Thomas Pornin 和其他幾位人士之間的 HACS 2018 討論中開發出來的。
遮罩載入位元的核心思想是 Jann Horn 在報告這些攻擊時提出的原始緩解措施的一部分。
間接分支、呼叫和返回¶
可以使用變種 #1 樣式的錯誤預測來攻擊條件分支以外的控制流程。
對虛擬方法的熱門呼叫目標的預測可能會導致在使用預期類型時對其進行推測性執行(通常稱為「類型混淆」)。
由於預測,熱門情況可能會被推測性執行,而不是作為跳轉表實作的 switch 語句的正確情況。
從函數返回時,熱門的常見返回位址可能會被錯誤預測。
這些程式碼模式也容易受到 Spectre 變種 #2 的攻擊,因此最好在 x86 平台上使用 retpoline 來緩解。當使用像 retpoline 這樣的緩解技術時,推測根本無法透過間接控制流程邊緣進行(或者在填滿 RSB 的情況下,它不會被錯誤預測),因此它也受到變種 #1 樣式攻擊的保護。然而,某些架構、微架構或供應商不採用 retpoline 緩解措施,並且在未來的 x86 硬體(Intel 和 AMD)上,由於基於硬體的緩解措施,預計它將變得不必要。
當不使用 retpoline 時,這些邊緣將需要獨立的保護,以防禦變種 #1 樣式的攻擊。與用於條件控制流程的類似方法應該有效
uintptr_t all_ones_mask = std::numerical_limits<uintptr_t>::max();
uintptr_t all_zeros_mask = 0;
void leak(int data);
void example(int* pointer1, int* pointer2) {
uintptr_t predicate_state = all_ones_mask;
switch (condition) {
case 0:
// Assuming ?: is implemented using branchless logic...
predicate_state = (condition != 0) ? all_zeros_mask : predicate_state;
// ... lots of code ...
//
// Harden the pointer so it can't be loaded
pointer1 &= predicate_state;
leak(*pointer1);
break;
case 1:
predicate_state = (condition != 1) ? all_zeros_mask : predicate_state;
// ... more code ...
//
// Alternative: Harden the loaded value
int value2 = *pointer2 & predicate_state;
leak(value2);
break;
// ...
}
}
核心思想保持不變:使用資料流驗證控制流程,並使用該驗證來檢查載入是否無法沿著錯誤推測的路徑洩漏資訊。通常,這涉及跨邊緣傳遞此類控制流程的所需目標,並在之後檢查其是否正確。請注意,雖然很容易認為這可以緩解變種 #2 攻擊,但事實並非如此。這些攻擊會轉向不包含檢查的任意小工具。
變種 #1.1 和 #1.2 攻擊:「邊界檢查繞過儲存」¶
除了核心變種 #1 攻擊之外,還有擴展此攻擊的技術。主要技術稱為「邊界檢查繞過儲存」,並在這篇研究論文中討論:https://people.csail.mit.edu/vlk/spectre11.pdf
我們將獨立分析這兩個變種。首先,變種 #1.1 的工作原理是在邊界檢查繞過後推測性地儲存到返回位址之上。然後,CPU 在返回的推測性執行期間最終使用此推測性儲存,這可能會將推測性執行導向二進制檔案中的任意小工具。讓我們看一個例子。
unsigned char local_buffer[4];
unsigned char *untrusted_data_from_caller = ...;
unsigned long untrusted_size_from_caller = ...;
if (untrusted_size_from_caller < sizeof(local_buffer)) {
// Speculative execution enters here with a too-large size.
memcpy(local_buffer, untrusted_data_from_caller,
untrusted_size_from_caller);
// The stack has now been smashed, writing an attacker-controlled
// address over the return address.
minor_processing(local_buffer);
return;
// Control will speculate to the attacker-written address.
}
然而,這可以透過強化返回位址的載入來緩解,就像任何其他載入一樣。這有時很複雜,因為例如 x86 隱式地從堆疊中載入返回位址。但是,下面的實作技術專門用於透過使用堆疊指標在函數之間傳達錯誤推測來緩解這種隱式載入。這還會導致錯誤推測具有無效的堆疊指標,並且永遠無法讀取推測性儲存的返回位址。請參閱下面的詳細討論。
對於變種 #1.2,攻擊者推測性地儲存到用於實作間接呼叫或間接跳轉的虛擬方法表或跳轉表中。由於這是推測性的,因此即使這些表儲存在唯讀頁面中,這通常也是可能的。例如
class FancyObject : public BaseObject {
public:
void DoSomething() override;
};
void f(unsigned long attacker_offset, unsigned long attacker_data) {
FancyObject object = getMyObject();
unsigned long *arr[4] = getFourDataPointers();
if (attacker_offset < 4) {
// We have bypassed the bounds check speculatively.
unsigned long *data = arr[attacker_offset];
// Now we have computed a pointer inside of `object`, the vptr.
*data = attacker_data;
// The vptr points to the virtual table and we speculatively clobber that.
g(object); // Hand the object to some other routine.
}
}
// In another file, we call a method on the object.
void g(BaseObject &object) {
object.DoSomething();
// This speculatively calls the address stored over the vtable.
}
緩解此問題需要強化從這些位置的載入,或緩解間接呼叫或間接跳轉。這些方法中的任何一種都足以阻止呼叫或跳轉使用已讀回的推測性儲存值。
對於這兩種情況,使用 retpoline 同樣足夠有效。一種可能的混合方法是將 retpoline 用於間接呼叫和跳轉,同時依靠 SLH 來緩解返回。
另一種對這兩種情況都足夠有效的方法是強化所有推測性儲存。然而,由於大多數儲存並不重要,並且不會固有地洩漏資料,因此考慮到它所防禦的攻擊,這預計會非常昂貴。
實作細節¶
有許多複雜的細節會影響此技術的實作,無論是在特定架構上還是在特定編譯器內。我們討論了針對 x86 架構和 LLVM 編譯器的提議實作技術。這些主要是作為範例,因為其他實作技術也是非常有可能的。
x86 實作細節¶
在 x86 平台上,我們將實作分解為三個核心組件:透過控制流程圖累積謂詞狀態、檢查載入,以及檢查程序之間的控制轉移。
累積謂詞狀態¶
考慮像以下這樣的基準 x86 指令,它們測試三個條件,如果全部通過,則從記憶體載入資料並可能透過某些側通道洩漏它
# %bb.0: # %entry
pushq %rax
testl %edi, %edi
jne .LBB0_4
# %bb.1: # %then1
testl %esi, %esi
jne .LBB0_4
# %bb.2: # %then2
testl %edx, %edx
je .LBB0_3
.LBB0_4: # %exit
popq %rax
retq
.LBB0_3: # %danger
movl (%rcx), %edi
callq leak
popq %rax
retq
當我們進行推測性執行載入時,我們想知道是否任何動態執行的謂詞已被錯誤推測。為了追蹤這一點,沿著每個條件邊緣,我們需要追蹤允許採取該邊緣的資料。在 x86 上,此資料儲存在條件跳轉指令使用的旗標暫存器中。沿著控制流程中此分支之後的兩個邊緣,旗標暫存器仍然有效,並包含可用於建立累積謂詞狀態的資料。我們使用 x86 條件移動指令來累積它,該指令也讀取狀態所在的旗標暫存器。已知這些條件移動指令在任何 x86 處理器上都不會被預測,使其免受可能重新引入漏洞的錯誤預測的影響。當我們插入條件移動時,程式碼最終看起來像這樣:
# %bb.0: # %entry
pushq %rax
xorl %eax, %eax # Zero out initial predicate state.
movq $-1, %r8 # Put all-ones mask into a register.
testl %edi, %edi
jne .LBB0_1
# %bb.2: # %then1
cmovneq %r8, %rax # Conditionally update predicate state.
testl %esi, %esi
jne .LBB0_1
# %bb.3: # %then2
cmovneq %r8, %rax # Conditionally update predicate state.
testl %edx, %edx
je .LBB0_4
.LBB0_1:
cmoveq %r8, %rax # Conditionally update predicate state.
popq %rax
retq
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
...
在這裡,我們透過將 %rax 歸零來建立「空的」或「正確執行」謂詞狀態,並透過將 -1 放入 %r8 來建立常數「不正確執行」謂詞值。然後,沿著從條件分支出來的每個邊緣,我們執行條件移動,在正確執行中,這將是一個空操作,但如果被錯誤推測,將用 %r8 的值替換 %rax。錯誤推測三個謂詞中的任何一個都會導致 %rax 從 %r8 中保存「不正確執行」值,因為我們在執行正確時保留傳入值,而不是覆蓋它。
我們現在在每個基本區塊的 %rax 中都有一個值,指示先前是否在某個時間點錯誤預測了謂詞。而且我們已經安排了該值在下面用於強化載入時特別有效。
間接呼叫、分支和返回謂詞¶
在追蹤間接呼叫、分支和返回時,沒有類似的旗標可以使用。謂詞狀態必須透過其他方式累積。從根本上說,這與 CFI 中提出的問題相反:我們需要檢查我們從哪裡來,而不是我們要去哪裡。對於函數本地跳轉表,這很容易安排,方法是在每個目標內測試跳轉表的輸入(尚未實作,請使用 retpoline)
pushq %rax
xorl %eax, %eax # Zero out initial predicate state.
movq $-1, %r8 # Put all-ones mask into a register.
jmpq *.LJTI0_0(,%rdi,8) # Indirect jump through table.
.LBB0_2: # %sw.bb
testq $0, %rdi # Validate index used for jump table.
cmovneq %r8, %rax # Conditionally update predicate state.
...
jmp _Z4leaki # TAILCALL
.LBB0_3: # %sw.bb1
testq $1, %rdi # Validate index used for jump table.
cmovneq %r8, %rax # Conditionally update predicate state.
...
jmp _Z4leaki # TAILCALL
.LBB0_5: # %sw.bb10
testq $2, %rdi # Validate index used for jump table.
cmovneq %r8, %rax # Conditionally update predicate state.
...
jmp _Z4leaki # TAILCALL
...
.section .rodata,"a",@progbits
.p2align 3
.LJTI0_0:
.quad .LBB0_2
.quad .LBB0_3
.quad .LBB0_5
...
返回在 x86-64(或其他具有所謂「紅色區域」的 ABI,該區域超出堆疊末端)上具有簡單的緩解技術。保證此區域在跨中斷和上下文切換時保持不變,這使得在返回到目前程式碼時使用的返回位址保留在堆疊上並且可以有效讀取。我們可以在呼叫者中發出程式碼,以驗證返回邊緣沒有被錯誤預測
callq other_function
return_addr:
testq -8(%rsp), return_addr # Validate return address.
cmovneq %r8, %rax # Update predicate state.
對於沒有「紅色區域」的 ABI(因此無法從堆疊中讀取返回位址),我們可以在呼叫之前計算預期的返回位址到跨呼叫保留的暫存器中,並以類似於上述的方式使用它。
間接呼叫(以及在沒有紅色區域 ABI 的情況下的返回)對傳播提出了最重大的挑戰。最簡單的技術是定義一個新的 ABI,以便將預期的呼叫目標傳遞到被呼叫的函數中,並在入口處進行檢查。不幸的是,在 C 和 C++ 中部署新的 ABI 非常昂貴。雖然目標函數可以在 TLS 中傳遞,但我們仍然需要複雜的邏輯來處理使用和不使用此額外邏輯編譯的函數混合(基本上,使 ABI 向後相容)。目前,我們建議在此處使用 retpoline,並將繼續研究緩解此問題的方法。
最佳化、替代方案和權衡¶
僅僅累積謂詞狀態就涉及相當大的成本。我們採用了幾種關鍵的最佳化來最小化這一點,以及在產生的程式碼中呈現不同權衡的各種替代方案。
首先,我們致力於減少用於追蹤狀態的指令數量
我們不是在原始程式碼的每個條件邊緣都插入
cmovCC指令,而是追蹤在進入每個基本區塊之前需要捕獲的每組條件旗標,並為這些旗標重複使用通用的cmovCC序列。當需要多個
cmovCC指令來捕獲旗標集時,我們可以進一步重複使用字尾。目前,人們認為這不值得付出成本,因為成對的旗標相對罕見,而它們的字尾則極為罕見。
x86 中的常見模式是有多個條件跳轉指令,它們使用相同的旗標但處理不同的條件。天真地說,我們可以將它們之間的每個 fallthrough 視為「邊緣」,但這會導致控制流程圖更加複雜。相反,我們累積 fallthrough 所需的條件集,並在單個 fallthrough 邊緣中使用
cmovCC指令序列來追蹤它。
其次,我們透過為「壞」狀態分配一個暫存器,以暫存器壓力換取更簡單的 cmovCC 指令。我們可以從記憶體中讀取該值作為條件移動指令的一部分,但是,這會產生更多的微操作,並需要載入-儲存單元參與。目前,我們將該值放入虛擬暫存器中,並允許暫存器分配器決定何時暫存器壓力足以使其值得溢出到記憶體並重新載入。
強化載入¶
一旦我們將謂詞累積為正確與錯誤推測的特殊值,我們需要將其應用於載入,以確保它們不會洩漏機密資料。有兩種主要的技術可以做到這一點:我們可以強化載入的值以防止觀察,或者我們可以強化位址本身以防止載入發生。這些方法具有顯著不同的效能權衡。
強化載入值¶
強化載入最吸引人的方法是遮罩所有載入的位元。關鍵要求是,對於每個載入的位元,沿著錯誤推測的路徑,無論載入的位元的值如何,該位元始終固定為 0 或 1。最明顯的實作是使用 and 指令,沿著錯誤推測的路徑使用全零遮罩,沿著正確的路徑使用全一遮罩,或者使用 or 指令,沿著錯誤推測的路徑使用全一遮罩,沿著正確的路徑使用全零遮罩。其他選項變得不太吸引人,例如乘以零或多個移位指令。由於我們在下面詳細闡述的原因,我們最終建議您使用 or 和全一遮罩,使 x86 指令序列看起來像這樣:
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
movl (%rsi), %edi # Load potentially secret data from %rsi.
orl %eax, %edi
其他有用的模式可能是將載入摺疊到 or 指令本身中,但代價是暫存器到暫存器的複製。
部署此方法存在一些挑戰
x86 上的許多載入都摺疊到其他指令中。分離它們會增加非常顯著且昂貴的暫存器壓力,並導致令人望而卻步的效能成本。
載入可能不會以通用暫存器為目標,這需要額外的指令將狀態值映射到正確的暫存器類別,以及可能更昂貴的指令以某種方式遮罩該值。
x86 上的旗標暫存器很可能處於活動狀態,並且以低成本方式保存它們具有挑戰性。
載入的值比用於載入的指標和索引多得多。因此,強化載入的結果比強化載入的位址(請參閱下文)需要更多的指令。
儘管存在這些挑戰,但強化載入的結果至關重要地允許載入繼續進行,因此對執行的總體推測性/亂序潛力的影響要小得多。還有幾種有趣的技術可以嘗試緩解這些挑戰,並使強化載入結果在至少某些情況下可行。然而,我們通常預計,當強化載入值變得無利可圖時,會退回到下一個方法,即強化位址本身。
摺疊到資料不變操作中的載入可以在操作後強化¶
使這可行性的第一個關鍵是認識到 x86 上的許多操作都是「資料不變」的。也就是說,它們沒有(已知的)可觀察到的行為差異,這是由於特定的輸入資料造成的。這些指令通常在實作處理私鑰資料的加密原語時使用,因為人們認為它們不會提供任何側通道。同樣,我們可以將強化延遲到它們之後,因為它們本身不會引入推測性執行側通道。這會產生如下所示的程式碼序列
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
addl (%rsi), %edi # Load and accumulate without leaking.
orl %eax, %edi
雖然對載入的(可能是機密的)值進行了加法運算,但這不會洩漏任何資料,然後我們立即強化它。
載入值的強化延遲到資料不變表達式圖中¶
我們可以概括之前的想法,並將強化下沉到表達式圖中,跨越盡可能多的資料不變操作。這可以使用非常保守的規則來判斷某事物是否是資料不變的。主要目標應該是用單個強化指令處理多個載入
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
addl (%rsi), %edi # Load and accumulate without leaking.
addl 4(%rsi), %edi # Continue without leaking.
addl 8(%rsi), %edi
orl %eax, %edi # Mask out bits from all three loads.
在 Haswell、Zen 和更新的處理器上強化載入值時保留旗標¶
遺憾的是,x86 上沒有任何有用的指令可以在不觸及旗標暫存器的情況下將遮罩應用於所有 64 位元。但是,我們可以透過將值零擴展到完整字長,然後使用 BMI2 shrx 指令向右移位至少原始位元數,來強化窄於一個字組的載入值(在 32 位元系統上少於 32 位元,在 64 位元系統上少於 64 位元)
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
addl (%rsi), %edi # Load and accumulate 32 bits of data.
shrxq %rax, %rdi, %rdi # Shift out all 32 bits loaded.
由於在 x86 上零擴展是免費的,因此這可以有效地強化載入的值。
強化載入的位址¶
當強化載入的值不適用時,通常是因為指令直接洩漏資訊(例如 cmp 或 jmpq),我們切換到強化載入的位址而不是載入的值。這避免了透過展開載入或支付其他高成本來增加暫存器壓力。
為了了解這在實務中是如何運作的,我們需要檢查 x86 定址模式的確切語意,其完整形式如下所示:(%base,%index,scale)offset。這裡,%base 和 %index 是 64 位元暫存器,它們可能具有任何值,並且可能受到攻擊者控制,而 scale 和 offset 是固定的立即值。scale 必須是 1、2、4 或 8,而 offset 可以是任何 32 位元符號擴展值。然後,用於尋找位址的確切計算為:在 64 位元二補數模算術下,%base + (scale * %index) + offset。
此方法的一個問題是,在強化之後,`%base + (scale *
那麼,一個大的正 offset 將索引到位址空間的前兩個 GB 內的記憶體中。雖然這些偏移量不受攻擊者控制,但攻擊者可以選擇攻擊碰巧具有所需偏移量的載入,然後成功讀取該區域中的記憶體。這大大增加了攻擊者的負擔,並限制了攻擊範圍,但並未消除它。為了完全阻止攻擊,我們必須與作業系統合作,以排除在位址空間的低 2GB 中映射記憶體。
64 位元載入檢查指令¶
我們可以使用以下指令序列來檢查載入。在這些範例中,我們設定 %r8 以保存特殊值 -1,該值將在錯誤推測的路徑中透過 cmov 移動到 %rax 上。
單一暫存器定址模式
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
orq %rax, %rsi # Mask the pointer if misspeculating.
movl (%rsi), %edi
雙暫存器定址模式
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
orq %rax, %rsi # Mask the pointer if misspeculating.
orq %rax, %rcx # Mask the index if misspeculating.
movl (%rsi,%rcx), %edi
這將導致接近零的負位址,或導致 offset 將位址空間包裝回小的正位址。對於大多數作業系統而言,小的負位址將在使用者模式下產生錯誤,但需要使用者可存取高位址空間的目標可能需要調整上面使用的確切序列。此外,低位址將需要被 OS 標記為不可讀,以完全強化載入。
RIP 相對定址甚至更容易破解¶
有一種常見的定址模式慣用語,它更難檢查:相對於指令指標的定址。我們無法更改指令指標暫存器的值,因此我們面臨更困難的問題,即透過僅更改 %index,強制 %base + scale * %index + offset 成為無效位址。我們唯一的優勢是攻擊者也無法修改 %base。如果我們使用上面的快速指令序列,但僅將其應用於索引,我們將始終存取 %rip + (scale * -1) + offset。如果攻擊者可以找到一個載入,其位址碰巧指向機密資料,那麼他們就可以訪問它。但是,載入器和基礎程式庫也可以簡單地拒絕在程式碼中任何文字的 2GB 範圍內映射堆積、資料段或堆疊,就像它可以保留位址空間的低 2GB 一樣。
旗標暫存器再次使一切變得困難¶
不幸的是,使用 orq 指令的技術在 x86 上有一個嚴重的缺陷。使狀態累積變得容易的正是旗標暫存器(包含謂詞),但這在這裡造成了嚴重的問題,因為它們可能處於活動狀態,並被載入指令或後續指令使用。在 x86 上,orq 指令設定旗標,並將覆蓋已存在的任何內容。這使得將它們插入指令流中非常危險。不幸的是,與強化載入值不同,我們在這裡沒有後備方案,因此我們必須提供完全通用的方法。
在產生這些序列時,我們必須做的第一件事是嘗試分析周圍的程式碼,以證明旗標實際上並未處於活動狀態或正在使用中。通常,它是由一些其他指令設定的,這些指令只是碰巧設定了旗標暫存器(很像我們的!),而沒有實際的依賴性。在這些情況下,可以直接插入這些指令是安全的。或者,我們可以將它們提前移動,以避免損壞使用的值。
然而,這最終可能是不可能的。在這種情況下,我們需要圍繞這些指令保留旗標
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
pushfq
orq %rax, %rcx # Mask the pointer if misspeculating.
orq %rax, %rdx # Mask the index if misspeculating.
popfq
movl (%rcx,%rdx), %edi
使用 pushf 和 popf 指令可以在我們插入的程式碼周圍保存旗標暫存器,但代價很高。首先,我們必須將旗標儲存到堆疊並重新載入它們。其次,這會導致堆疊指標被動態調整,從而需要使用框架指標來引用溢出到堆疊的臨時變數等。
在較新的 x86 處理器上,我們可以使用 lahf 和 sahf 指令將所有旗標(溢位旗標除外)保存在暫存器中,而不是堆疊上。然後,我們可以使用 seto 和 add 在暫存器中保存和還原溢位旗標。總之,這將以與上述相同的方式保存和還原旗標,但使用兩個暫存器而不是堆疊。在大多數情況下,這仍然非常昂貴,即使比 pushf 和 popf 稍微便宜一些。
Haswell、Zen 和更新處理器上的無旗標替代方案¶
從 Haswell 和 Zen 處理器開始提供的 BMI2 x86 指令集擴充功能,有一個指令用於位元移位,且不會設定任何旗標:shrx。我們可以利用這個指令和 lea 指令來實作與上述程式碼序列類似的程式碼序列。然而,這些指令仍然稍微慢一些,因為在大多數現代 x86 處理器中,能夠調度移位指令的埠口比能夠調度 or 指令的埠口更少。
快速、單一暫存器定址模式
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
shrxq %rax, %rsi, %rsi # Shift away bits if misspeculating.
movl (%rsi), %edi
這會將暫存器縮減為零或一,並且定址模式中除了偏移量以外的所有內容都小於或等於 9。這表示完整位址只能保證小於 (1 << 31) + 9。作業系統可能希望保護額外一頁的低位址空間來解決這個問題
最佳化¶
這種方法的大部分成本來自於以這種方式檢查載入,因此最佳化這一點非常重要。然而,除了使應用檢查的指令序列有效率(例如,避免 pushfq 和 popfq 序列)之外,唯一顯著的最佳化是在不引入漏洞的情況下減少檢查的載入次數。我們應用幾種技術來實現這一點。
不要檢查來自編譯時期常數堆疊偏移量的載入¶
我們在 x86 上實作此最佳化,方法是跳過檢查使用固定框架指標偏移量的載入。
此最佳化的結果是,像重新載入溢出暫存器或存取全域欄位這樣的模式不會被檢查。這是一個非常顯著的效能提升。
不要檢查相依載入¶
這種緩解策略之所以有效,核心部分原因在於它建立了對載入位址的資料流檢查。然而,這表示如果位址本身已經使用經過檢查的載入來載入,則無需檢查相依載入,前提是它與經過檢查的載入位於相同的基本區塊內,因此沒有額外的述詞來保護它。考慮如下程式碼
...
.LBB0_4: # %danger
movq (%rcx), %rdi
movl (%rdi), %edx
這將轉換為
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
orq %rax, %rcx # Mask the pointer if misspeculating.
movq (%rcx), %rdi # Hardened load.
movl (%rdi), %edx # Unhardened load due to dependent addr.
這不會檢查透過 %rdi 的載入,因為該指標已相依於一個經過檢查的載入。
使用單一 lfence 保護大型、載入密集區塊¶
在一個區塊的開頭使用單一 lfence 指令可能是值得的,該區塊以大量需要獨立保護且需要強化載入位址的載入開始。然而,這在實務中不太可能有利可圖。強化的延遲損失需要超過正確推測執行的 lfence 的延遲損失。但在這種情況下,lfence 成本完全是推測執行的損失(至少)。到目前為止,我們關於使用 lfence 的效能成本的證據表明,幾乎沒有任何熱門程式碼模式可以使這種權衡變得合理。
誘人的最佳化,但會破壞安全模型¶
考慮過幾種最佳化,但由於未能維護安全模型而沒有成功。其中一個特別值得討論,因為許多其他的最佳化都會簡化為它。
我們想知道是否只能檢查基本區塊中的第一個載入。如果檢查按預期工作,它會形成一個無效的指標,甚至無法在硬體中進行虛擬位址轉換。它應該在其處理過程中很早就發生錯誤。也許這會在推測錯誤的路徑洩漏任何秘密之前及時阻止事情發生。但這最終無法奏效,因為處理器從根本上是亂序執行的,即使在其推測領域也是如此。因此,攻擊者可能會導致初始位址計算本身停滯,並允許任意數量的無關載入(包括攻擊機密資料的載入)通過。
跨程序檢查¶
現代 x86 處理器可能會推測執行到被呼叫的函式中,並從函式推測執行到其返回位址。因此,我們需要一種方法來檢查在推測錯誤的述詞之後發生的載入,但載入和推測錯誤的述詞位於不同的函式中。本質上,我們需要述詞狀態追蹤的某種跨程序泛化。在函式之間傳遞述詞狀態的主要挑戰是,我們希望不需要更改 ABI 或呼叫慣例,以便使這種緩解措施更易於部署,並且更進一步地希望以這種方式緩解的程式碼可以輕鬆地與未以這種方式緩解的程式碼混合,而不會完全喪失緩解措施的價值。
將述詞狀態嵌入到堆疊指標的高位元中¶
我們可以使用與強化指標相同的技術,將述詞狀態傳入和傳出函式。堆疊指標在函式之間可以輕鬆傳遞,我們可以測試它是否設定了高位元,以偵測它何時因推測錯誤而被標記。呼叫點指令序列看起來像這樣(假設推測錯誤的狀態值為 -1)
...
.LBB0_4: # %danger
cmovneq %r8, %rax # Conditionally update predicate state.
shlq $47, %rax
orq %rax, %rsp
callq other_function
movq %rsp, %rax
sarq 63, %rax # Sign extend the high bit to all bits.
這首先將述詞狀態放入 %rsp 的高位元中,然後再呼叫函式,然後從 %rsp 的高位元中讀取出來。當正確執行(推測或非推測)時,這些都是空操作。當推測錯誤時,堆疊指標將變為負數。我們安排使其保持規範位址,但其他方面保持低位元不變,以允許堆疊調整正常進行,而不會中斷此操作。在被呼叫的函式中,我們可以提取此述詞狀態,然後在返回時重設它
other_function:
# prolog
callq other_function
movq %rsp, %rax
sarq 63, %rax # Sign extend the high bit to all bits.
# ...
.LBB0_N:
cmovneq %r8, %rax # Conditionally update predicate state.
shlq $47, %rax
orq %rax, %rsp
retq
當所有程式碼都以這種方式緩解時,此方法是有效的,甚至可以在非常有限的範圍內存活到未緩解的程式碼中(狀態將在未緩解的函式中來回傳遞,只是不會被更新)。但它確實有一些限制。將狀態合併到 %rsp 中存在成本,並且它無法將緩解的程式碼與未緩解的呼叫者中的推測錯誤隔離開來。
使用這種形式的跨程序緩解還有一個優點:透過形成這些無效的堆疊指標位址,我們可以防止推測返回成功讀取推測寫入到實際堆疊的值。這首先透過在計算堆疊上返回位址的位址和我們的述詞狀態之間形成資料相依性來實現。即使滿足條件,如果錯誤預測導致狀態中毒,則產生的堆疊指標也將無效。
重寫內部函式的 API 以直接傳播述詞狀態¶
(尚未實作。)
對於內部函式,我們可以選擇直接調整其 API 以接受述詞作為參數並返回它。對於進入函式而言,這可能比嵌入到 %rsp 中稍微便宜一些。
使用 lfence 來保護函式轉換¶
可以使用 lfence 指令來防止後續載入在所有先前的錯誤預測述詞解析之前推測執行。我們可以將此更廣泛的屏障用於函式之間推測載入的執行。我們在進入區塊中發出它以處理呼叫,並在每次返回之前發出它。這種方法還具有在與未緩解的程式碼混合時提供最強緩解程度的優點,方法是停止所有進入已緩解函式的推測錯誤,而不管呼叫者中發生了什麼。然而,這種混合本質上更具風險。這種混合是否足以作為緩解措施需要仔細分析。
不幸的是,實驗結果表明,對於某些程式碼模式,這種方法的效能開銷非常高。一個典型的例子是任何形式的遞迴評估引擎。當使用 lfence 緩解時,熱門、快速的呼叫和返回序列會表現出顯著的效能損失。僅此組件就可能使效能降低 2 倍或更多,即使僅在混合程式碼中使用,這也是一個令人不快的權衡。
使用內部 TLS 位置來傳遞述詞狀態¶
我們可以定義一個特殊的執行緒本機值,以在函式之間保存述詞狀態。這透過使用呼叫者和被呼叫者之間的側通道來傳達述詞狀態,從而避免了直接的 ABI 影響。它還允許狀態的隱式零初始化,這允許未檢查的程式碼成為第一個執行的程式碼。
然而,這需要在進入區塊中從 TLS 載入,在每次呼叫和每次 ret 之前儲存到 TLS,以及在每次呼叫之後從 TLS 載入。因此,預計即使比在函式進入區塊中使用 %rsp 和潛在的 lfence 也要昂貴得多。
定義新的 ABI 和/或呼叫慣例¶
我們可以定義新的 ABI 和/或呼叫慣例,以顯式地傳入和傳出函式的述詞狀態。如果沒有其他替代方案具有足夠的效能,這可能會很有趣,但它會使部署和採用變得異常複雜,並且可能不可行。
高階替代緩解策略¶
對於緩解變體 1 攻擊,還有完全不同的替代方法。大多數 討論 到目前為止,重點是透過手動重寫程式碼以包含不易受攻擊的指令序列,來緩解 Linux 核心(或其他核心)中特定的已知可攻擊組件。對於 x86 系統,這是透過在如果推測執行會洩漏資料的程式碼路徑中注入 lfence 指令,或透過將記憶體存取重寫為對已知安全區域進行無分支遮罩來完成的。在 Intel 系統上,lfence 將防止機密資料的推測載入。在 AMD 系統上,lfence 目前是空操作,但可以透過設定 MSR 使其成為調度序列化,從而排除程式碼路徑的錯誤推測(緩解 G-2 + V1-1)。
然而,這依賴於尋找和列舉程式碼中所有可能被攻擊以洩漏資訊的點。雖然在某些情況下,靜態分析可以有效地大規模執行此操作,但在許多情況下,它仍然依賴於人類的判斷來評估程式碼是否可能容易受到攻擊。特別是對於那些接受較少詳細審查但仍然對這些攻擊敏感的軟體系統,這似乎是一個不切實際的安全模型。我們需要一種自動且系統化的緩解策略。
條件邊緣上的自動 lfence¶
擴展現有手動編碼緩解措施的一種自然方法是簡單地將 lfence 指令注入到每個條件分支的目標和後續路徑目的地中。這確保了沒有述詞或邊界檢查可以被推測性地繞過。然而,這種方法的效能開銷簡而言之是災難性的。然而,它仍然是此工作之前唯一已知的真正「預設安全」方法,並作為效能的基準。
解決此效能開銷並使其更實際部署的一種嘗試是 MSVC 的 /Qspectre 開關。他們的技術是在編譯器內使用靜態分析,僅將 lfence 指令插入到有攻擊風險的條件邊緣中。然而,初步 分析 表明,這種方法是不完整的,並且僅捕獲了可攻擊模式的一個小而有限的子集,這些模式恰好非常類似於最初的概念驗證。因此,雖然其效能是可以接受的,但它似乎不是一種足夠系統化的緩解措施。
效能開銷¶
這種全面緩解風格的效能開銷非常高。然而,它與先前建議的方法(例如 lfence 指令)相比,非常有優勢。正如使用者可以限制 lfence 的範圍以控制其效能影響一樣,這種緩解技術也可以限制範圍。
然而,重要的是要了解獲得完全緩解的基準的成本是多少。在這裡,我們假設目標是 Haswell(或更新)處理器,並使用所有技巧來提高效能(因此使低 2gb 不受保護,以及程式中任何 PC 周圍的 +/- 2gb)。我們運行了 Google 的微基準測試套件和一個使用 ThinLTO 和 PGO 建構的大型高度調整的伺服器。所有這些都是使用 -march=haswell 建構的,以存取 BMI2 指令,基準測試在大型 Haswell 伺服器上運行。我們收集了基於 lfence 的緩解措施和此處提出的載入強化的資料。摘要是,使用載入強化進行緩解比使用 lfence 進行緩解快 1.77 倍,並且與正常程式相比,載入強化的開銷可能在 10% 到 50% 之間,大多數大型應用程式的開銷為 30% 或更少。
基準測試 |
|
載入強化 |
緩解後的加速 |
|---|---|---|---|
Google 微基準測試套件 |
-74.8% |
-36.4% |
2.5 倍 |
大型伺服器 QPS(使用 ThinLTO 和 PGO) |
-62% |
-29% |
1.8 倍 |
以下是微基準測試套件結果的可視化,有助於顯示摘要中有些遺失的結果分佈。y 軸是載入強化相對於 lfence 的對數刻度加速比(向上 -> 更快 -> 更好)。每個箱形圖和鬚狀線代表一個微基準測試,該基準測試可能具有許多不同的測量指標。紅線標記中位數,方框標記第一四分位數和第三四分位數,鬚狀線標記最小值和最大值。
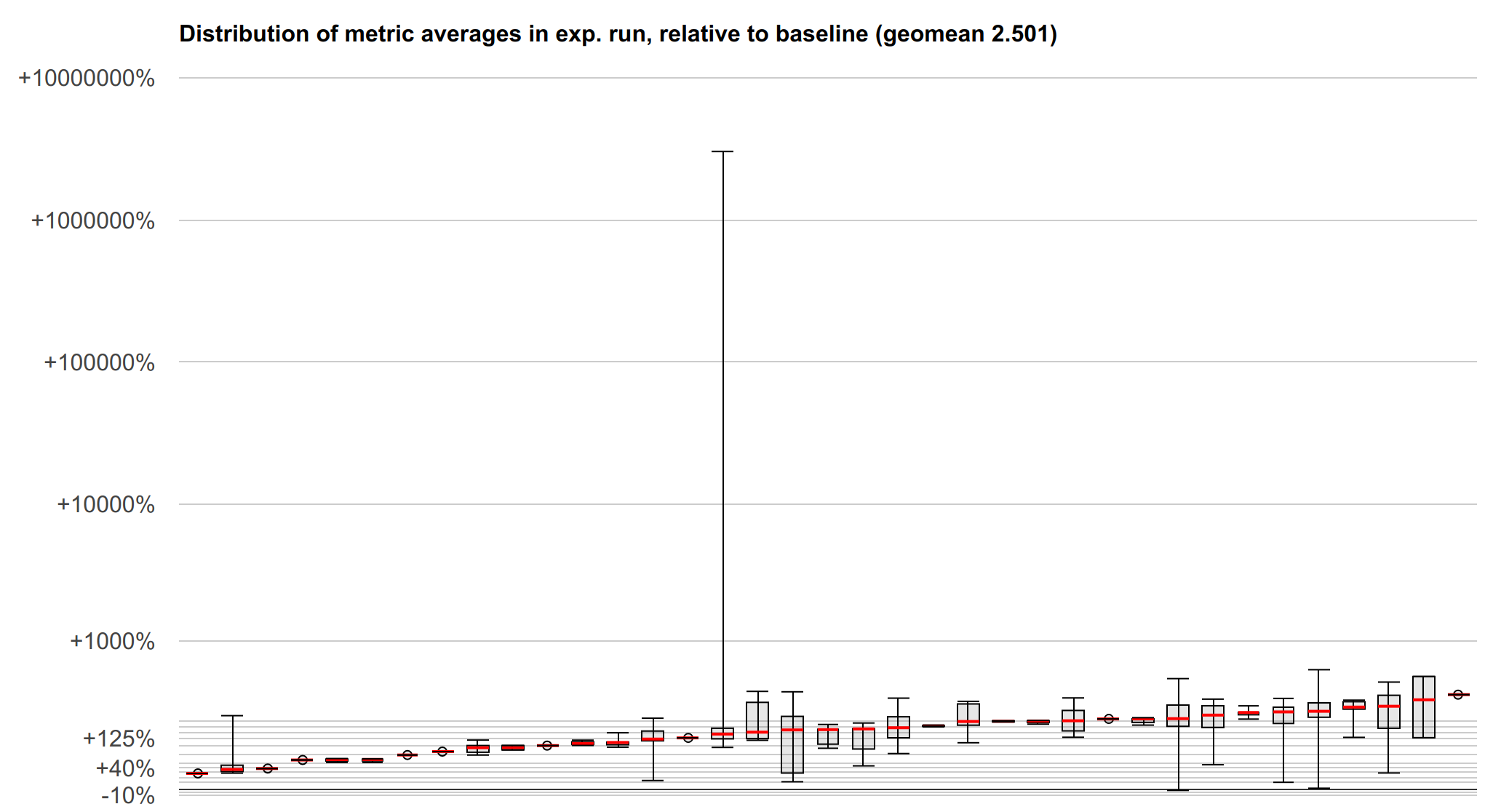
我們還沒有關於 SPEC 或 LLVM 測試套件的基準測試資料,但我們可以努力獲得這些資料。儘管如此,以上內容應該可以清楚地描述效能,並且特定的基準測試不太可能揭示特別有趣的屬性。
未來工作:細粒度控制和 API 整合¶
這種技術的效能開銷可能非常顯著,使用者希望控制或降低它。這裡有一些有趣的選項會影響所使用的實作策略。
一個特別有吸引力的選項是允許在相當細的粒度下選擇加入和選擇退出這種緩解措施,例如在每個函式的基礎上,包括智慧型處理內聯決策——受保護的程式碼可以防止內聯到未受保護的程式碼中,而未受保護的程式碼在內聯到受保護的程式碼中時將變得受保護。對於只有有限的程式碼集可由外部控制的輸入存取的系統,可能可以透過這種機制來限制緩解措施的範圍,而不會損害應用程式的整體安全性。效能影響也可能集中在少數關鍵函式中,這些函式可以手動緩解,從而降低效能開銷,而應用程式的其餘部分則接受自動保護。
對於限制緩解措施的範圍或手動緩解熱門函式,需要一些支援來混合緩解和未緩解的程式碼,而不會完全破壞緩解措施。對於第一種用例,特別希望緩解的程式碼在從未緩解的程式碼推測錯誤呼叫期間保持安全。
對於第二種用例,將自動緩解技術連接到顯式緩解 API(例如 http://wg21.link/p0928 中描述的 API(或任何其他最終 API))可能很重要,以便有一種乾淨的方法從自動緩解切換到手動緩解,而不會立即暴露漏洞。然而,在 API 更好地建立之前,如何做到這一點的設計很難提出。我們將在這些 API 成熟後重新審視這一點。