在 big endian 模式中使用 ARM NEON 指令¶
簡介¶
為 big endian ARM 處理器產生程式碼在大多數情況下都很直接。然而,NEON 的載入和儲存有一些有趣的特性,這使得在 big endian 模式下程式碼產生的決策變得不那麼明顯。
本文檔的目的是解釋 NEON 載入和儲存的問題,以及 LLVM 中已實作的解決方案。
在本文檔中,「向量」一詞指的是 ARM ABI 所謂的「短向量」,它是一個可以容納在 NEON 暫存器中的項目序列。此序列的長度可以是 64 或 128 位元,並且可以構成 8、16、32 或 64 位元的項目。本文檔通篇指的是 A64 指令,但幾乎適用於 A32/ARMv7 指令集。A32 中傳遞向量的 ABI 格式與 A64 略有不同。除此之外,相同的概念適用。
範例:C 語言層級的內建函數 -> 組合語言¶
首先說明 C 語言層級的 ARM NEON 內建函數如何降低為指令,這可能會有所幫助。
這個簡單的 C 函數接受一個包含四個整數的向量,並將第零個 lane 設定為值 “42”
#include <arm_neon.h>
int32x4_t f(int32x4_t p) {
return vsetq_lane_s32(42, p, 0);
}
arm_neon.h 內建函數在可能的情況下產生「通用」IR(也就是說,正常的 IR 指令而不是 llvm.arm.neon.* 內建函數呼叫)。以上程式碼產生
define <4 x i32> @f(<4 x i32> %p) {
%vset_lane = insertelement <4 x i32> %p, i32 42, i32 0
ret <4 x i32> %vset_lane
}
然後變成以下簡單的組合語言
f: // @f
movz w8, #0x2a
ins v0.s[0], w8
ret
問題¶
主要問題是向量在記憶體和暫存器中的表示方式。
首先,回顧一下。「endianness」僅影響項目在記憶體中的表示方式。在暫存器中,數字只是一個位元序列 - 在 AArch64 通用暫存器的情況下為 64 位元。然而,記憶體是一個 8 位元大小的可定址單元序列。因此,任何大於 8 位元的數字都必須分成 8 位元的區塊,而 endianness 描述了這些區塊在記憶體中佈局的順序。
「little endian」佈局將最低有效位元組放在最前面(記憶體位址最低)。「big endian」佈局將最高有效位元組放在最前面。這表示當從 big endian 記憶體載入項目時,記憶體中最低的 8 位元必須進入最高的 8 位元,依此類推。
LDR 和 LD1¶
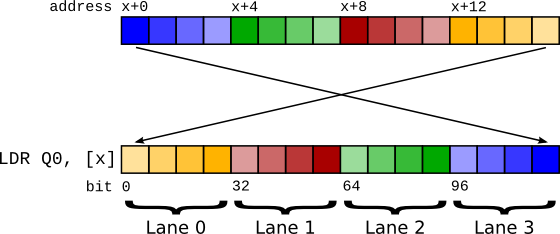
圖 1 使用 LDR 的 Big endian 向量載入。¶
向量是同時運算的連續項目序列。為了載入 64 位元向量,需要從記憶體讀取 64 位元。在 little endian 模式下,我們可以透過執行 64 位元載入來做到這一點 - LDR q0, [foo]。但是,如果我們在 big endian 模式下嘗試這樣做,由於位元組交換,lane 索引最終會被交換!記憶體中佈局的第零個項目變成向量中的第 n 個 lane。
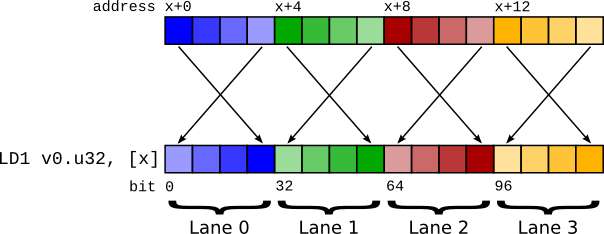
圖 2 使用 LD1 的 Big endian 向量載入。請注意,lane 保留了正確的順序。¶
因此,指令 LD1 執行向量載入,但不是對整個 64 位元執行位元組交換,而是對向量內的個別項目執行位元組交換。這表示暫存器內容與在 little endian 系統上相同。
似乎 LD1 應該足以在 big endian 機器上執行向量載入。然而,這兩種方法都有優缺點,使得選擇哪種暫存器格式變得不太簡單。
有兩個選項
向量暫存器的內容與使用
LDR指令載入的內容相同。向量暫存器的內容與使用
LD1指令載入的內容相同。
因為 LD1 == LDR + REV,類似地 LDR == LD1 + REV(在 big endian 系統上),我們可以透過另一種類型的載入加上 REV 指令來模擬任一種類型的載入。因此,我們不是決定要使用哪些指令,而是決定要使用哪種格式(這將影響最適合使用的指令)。
請注意,在本節中,我們僅提及載入。儲存也存在完全相同的問題,因此為了簡潔起見而跳過。
考量¶
LLVM IR Lane 排序¶
LLVM IR 具有一流的向量類型。在 LLVM IR 中,向量的第零個元素駐留在最低的記憶體位址。最佳化器在某些領域依賴此屬性,例如在將向量串連在一起時。目的是讓陣列和向量具有相同的記憶體佈局 - [4 x i8] 和 <4 x i8> 在記憶體中應該以相同的方式表示。如果沒有此屬性,最佳化器將不得不巧妙地處理許多特殊情況。
使用 LDR 會破壞此 lane 排序屬性。這並不排除使用 LDR,但我們必須執行以下兩件事之一
在每次
LDR之後插入REV指令以反轉 lane 順序。停用所有依賴 lane 佈局的最佳化,並針對每次存取個別 lane (
insertelement/extractelement/shufflevector) 反轉 lane 索引。
AAPCS¶
ARM 程序呼叫標準 (AAPCS) 定義了在函數之間以暫存器傳遞向量的 ABI。它指出
當在暫存器和記憶體之間傳輸短向量時,它被視為不透明的物件。也就是說,短向量儲存在記憶體中,就好像它是使用單個
STR儲存整個暫存器一樣;短向量是使用對應的LDR指令從記憶體載入的。在 little-endian 系統上,這表示元素 0 將始終包含短向量的最低位址元素;在 big-endian 系統上,元素 0 將包含短向量的最高位址元素。—ARM 64 位元架構 (AArch64) 的程序呼叫標準,4.1.2 短向量
使用 ABI 定義的 LDR 和 STR 至少比 LD1 和 ST1 有一個優點。LDR 和 STR 不會注意到向量個別 lane 的大小。LD1 和 ST1 則不然 - lane 大小編碼在其中。這在 ABI 邊界上很重要,因為有必要知道被呼叫者期望的 lane 寬度。考慮以下程式碼
<callee.c>
void callee(uint32x2_t v) {
...
}
<caller.c>
extern void callee(uint32x2_t);
void caller() {
callee(...);
}
如果 callee 將其簽名變更為 uint16x4_t,這在暫存器內容中是等效的,如果我們以 LD1 傳遞,我們將破壞此程式碼,直到 caller 更新並重新編譯。
有一種論點是,如果兩個函數的簽名不同,則行為應該是未定義的。但是,可能有一些函數對向量的 lane 佈局不可知,並且在 ABI 邊界上沒有通用格式的情況下,將向量視為不透明值(僅載入和儲存它)是不可能的。
因此,為了保持 ABI 相容性,我們需要在函數呼叫之間使用 LDR lane 佈局。
對齊¶
在嚴格對齊模式下,LDR qX 要求其位址為 128 位元對齊,而 LD1 僅要求其與 lane 大小對齊即可。如果我們標準化為使用 LDR,我們仍然需要在某些地方使用 LD1 以避免對齊錯誤(LD1 的結果然後需要使用 REV 反轉)。
但是,大多數作業系統都不會在啟用對齊錯誤的情況下執行,因此這通常不是問題。
摘要¶
下表總結了對於上述提及的每個屬性,以及兩種解決方案中的每一種,需要發出的指令。
|
|
|
|---|---|---|
Lane 排序 |
|
|
AAPCS |
|
|
嚴格模式的對齊 |
|
|
兩種方法都不是完美的,選擇其中一種歸結為選擇兩害相權取其輕。lane 排序的問題,經決定,將不得不更改目標不可知的編譯器傳遞,並將導致奇怪的 IR,其中 lane 索引被反轉。經決定,這比必須進行的更改以支援 LD1 更糟,因此選擇 LD1 作為標準向量載入指令(並由此推斷,ST1 用於向量儲存)。
實作¶
實作分為 3 個部分
預先阻止
LDR和STR指令,使其永遠不允許被選取來產生向量載入和儲存。例外情況是單 lane 向量 [1] - 這些根據定義不可能有 lane 排序問題,因此可以使用LDR/STR。為位元轉換建立程式碼產生模式,以建立
REV指令。確保建立適當的位元轉換,以便向量值以 1 元素向量的形式在呼叫邊界上傳遞(這與使用
LDR載入它們的情況相同)。
位元轉換¶
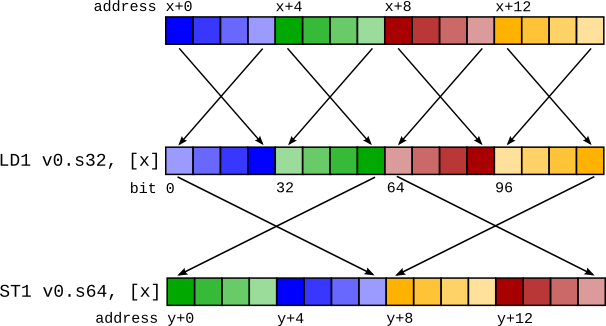
LD1 解決方案的主要問題是處理位元轉換(或位元鑄造,或重新解釋鑄造)。這些是偽指令,僅更改編譯器對資料的解釋,而不是底層資料本身。一個要求是,如果資料被載入然後再次儲存(稱為「往返」),則儲存後的記憶體內容應與載入前相同。如果載入向量,然後在儲存之前將其位元轉換為不同的向量類型,則目前會破壞往返。
以以下程式碼序列為例
%0 = load <4 x i32> %x
%1 = bitcast <4 x i32> %0 to <2 x i64>
store <2 x i64> %1, <2 x i64>* %y
這將產生如右圖所示的程式碼序列。不匹配的 LD1 和 ST1 導致儲存的資料與載入的資料不同。
當我們看到從類型 X 到類型 Y 的位元鑄造時,我們需要做的是更改資料的暫存器內表示,使其就好像它剛被類型 Y 的 LD1 載入一樣。
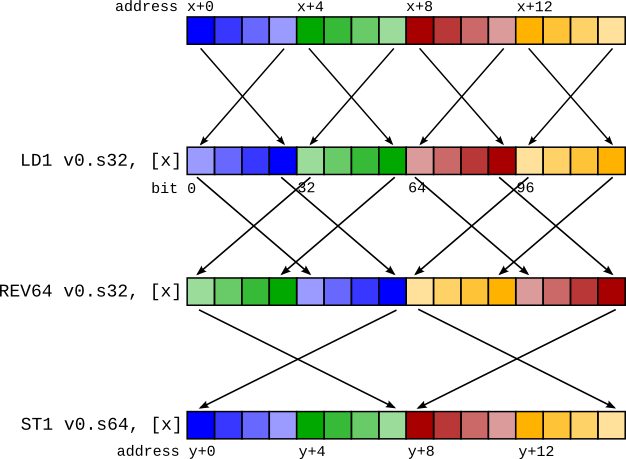
從概念上講,這很簡單 - 我們可以插入一個 REV 來撤銷類型 X 的 LD1(將暫存器內表示轉換為與 LDR 載入的表示相同),然後插入另一個 REV 以將表示更改為與類型 Y 的 LD1 載入的表示相同。
對於前面的範例,這將是
LD1 v0.4s, [x]
REV64 v0.4s, v0.4s // There is no REV128 instruction, so it must be synthesizedcd
EXT v0.16b, v0.16b, v0.16b, #8 // with a REV64 then an EXT to swap the two 64-bit elements.
REV64 v0.2d, v0.2d
EXT v0.16b, v0.16b, v0.16b, #8
ST1 v0.2d, [y]
事實證明,這些 REV 對幾乎在所有情況下都可以合併為單個 REV。對於上面的範例,REV128 4s + REV128 2d 實際上是一個 REV64 4s,如右圖所示。